ภาคผนวก C — การเชื่อมโยงข้อมูล (Data linkage)
เว็บไซต์นี้อยู่ระหว่างจัดทำ จึงยังมีเนื้อหาไม่ครบถ้วน
ท่านสามารถร่วมเพิ่มเติมหรือแก้ไขเนื้อหาต่าง ๆ ได้ที่ GitHub: sidataplus/omop-book
การเชื่อมโยงข้อมูล คือ การนำข้อมูลสุขภาพจากหลากหลายแหล่งมารวมกัน เช่น ข้อมูลจากโรงพยาบาล (Electronic Health Records หรือ EHR) และข้อมูลการเบิกจ่าย (Claims data) เป็นต้น เพื่อให้ได้ข้อมูลของผู้ป่วยแต่ละรายที่ครบถ้วนมากยิ่งขึ้น (holistic view) เช่น ข้อมูลจาก EHR โรงพยาบาลหนึ่งจะไม่ข้อมูลจากโรงพยาบาลอื่น ๆ ทั้งก่อนและหลังจากได้รับบริการที่โรงพยาบาลนั้น ๆ ในขณะเดียวกันข้อมูลการเบิกจ่าย มักจะไม่มีข้อมูลการบันทึกของแพทย์ ผลการตรวจทางห้องปฏิบัติการ และรายละเอียดการได้รับยา เป็นต้น
C.1 กระบวนการเชื่อมโยง
การใช้ Common Data Model เช่น OMOP CDM ทำให้ข้อมูลจากหลากหลายแหล่งมีรูปแบบโครงสร้างข้อมูลเหมือนกัน จึงสามารถนำข้อมูลมารวมกันได้ง่ายขึ้น
การ Matching ผู้ป่วย โดยทั่วไปมี 2 วิธีการ
- Unique patient identifiers เช่น เลขประจำตัวประชาชน
- Probabilistic matching โดยการใช้ข้อมูลหลายส่วนประกอบกัน เช่น ชื่อ นามสกุล วันเกิด เพศ เป็นต้น
C.2 การเชื่อมโยงข้อมูล OMOP CDM ในประเทศไทย
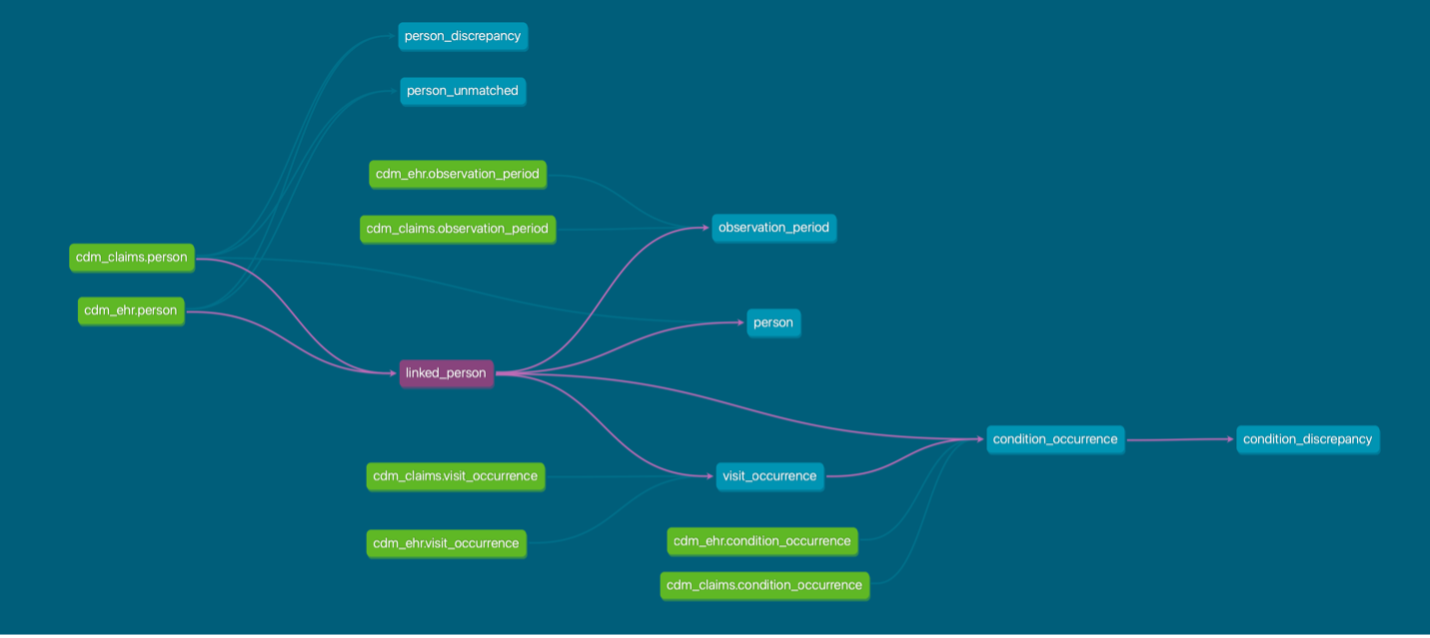
เนื่องจากประชากรไทยมีเลขประจำตัวประชาชนทุกคนจึงสามารถ match unique patient identifier ได้โดยตรง เมื่อข้อมูลถูกแปลงเป็นมาตรฐาน OMOP CDM แล้ว สามารถนำมาเชื่อมโยงกันได้โดยผ่านเลขประจำตัวประชาชนที่ผ่านการ hash แล้วที่เก็บใน field person_source_value ของ table person โดยจะต้องมีการเรียงลำดับเลข person_id, visit_occurrence_id และ id ใน transaction tables ต่าง ๆ ใหม่ เนื่องจากข้อมูลจาก 2 แหล่งอาจมีเลข id ที่ซ้ำกัน
ทั้งนี้ข้อมูลที่ซ้ำกันเช่น การวินิจฉัย (condition_occurrence) หัตถการ (procedure_occurrence) เป็นต้น มีการระบุแหล่งที่มาในข้อมูลที่เชื่อมไว้อยู่แล้ว ([condition/procedure]_type_concept_id) จึงไม่มีปัญหาในการนำไปใช้ทำวิจัย เว้นแต่ว่า การบันทึกกิจกรรมข้างต้น มีวันที่คาดเคลื่อนกันมาก จะมีผลต่อการวิจัย จึงต้องมีการเขียนการทดสอบเพื่อรายงานความคลาดเคลื่อนเหล่านี้ไว้ด้วย
Script การเชื่อมโยงข้อมูล: GitHub sidataplus/omop_linkage_dbt
ตัวอย่าง data lineage ของการเชื่อมโยงข้อมูล